记一次node爬虫经历
本文最后更新于: 2022年10月10日 下午
需求说明
- 访问网站
- 获取列表页数据
- 循环列表页数据获取每条数据对应的详情页数据
- 机构名称
- 机构类型
- 机构性质
- 联系人
- 固定电话
- 联系电话
- 联系地址
- 导出 excel
开发环境
- Mac OS v10.15.7
- node v12.16.1
- 用到 npm 包
1 | |
准备工作
- cheerio 学习操作语法 基本跟 jQuery 一致
- request 请求模块的基本使用
- puppeteer 无头浏览器的基本使用
- node fs 文件模块的基本使用
遇到的问题:
页面中的数据是 ajax 加载出来的
刚开始使用 request 直接请求页面,发现响应回来的 html 文档并不是完整的,页面上有 ajax 请求,动态生成了一部分 DOM , 我原本想分析它这个 ajax 请求的接口,发现请求地址上有个查询字符串,像这样:?ajaxtype=yanglaoxx_showlianxi&rand=0.17592822223231708
不懂这个 rand 值是怎么计算出来的,实在不想再去扒网站 js 的代码,于是想到用无头浏览器来渲染完整网页;
这里我使用 puppeteer 渲染完整的网页
1 | |
我只安装了 puppeteer-core 核心,使用 puppeteer-core需要手动指定已安装的 Chrome 浏览器的安装路径。Mac电脑上Chrome浏览器的的安装路径,可以通过在浏览器中输入 chrome:\\version 来查看。
1 | |
这是 puppeteer 返回的完整 html 结构,包含了 ajax 请求动态生成的 DOM 结构: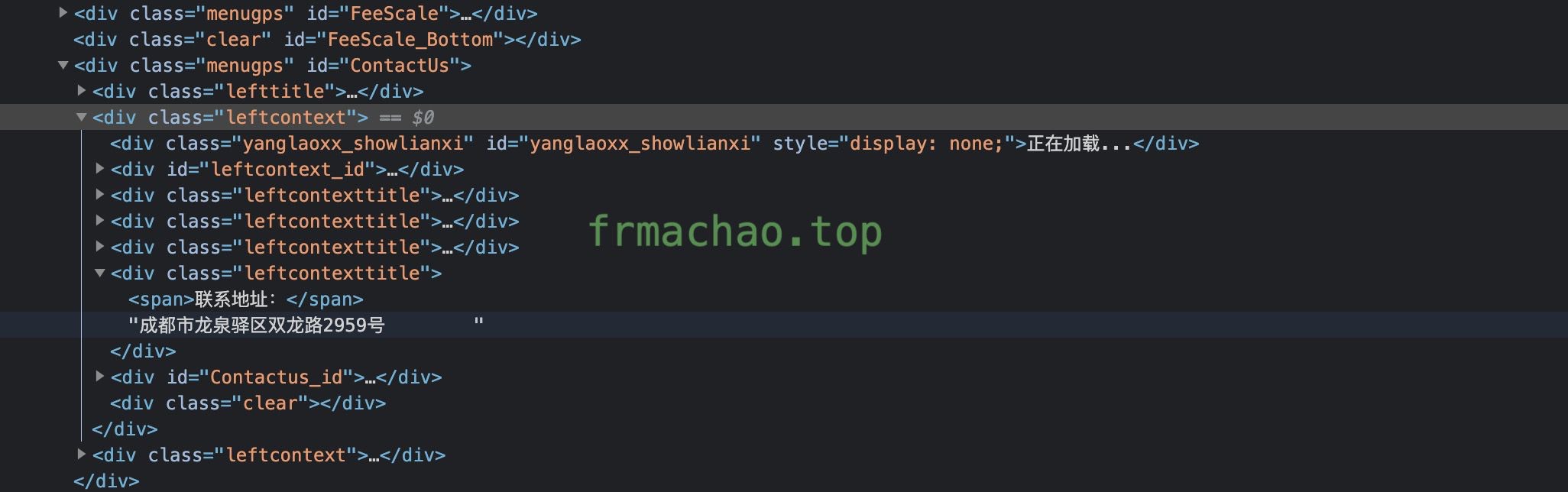
我现在遇到一个问题:在 puppeteer 中使用 cheerio 解析 html 文档 和 在浏览器使用 jquery 的表现不同。
疑问: 这两种 dom 选择有区别吗?
1 | |
网站反爬
遇到 pyppeteer.errors.TimeoutError: Navigation Timeout Exceeded: 30000 ms exceeded
爬取详情页时,访问次数多了 puppeteer 就会报错响应超时 我的思路是让 puppeteer 打开页面前等待 3-10 秒,同时让 puppeteer 等待网站响应的时间无限长
1 | |
需要再去研究的
- load networkidle0 domcontentloaded 三者的区别?
- 在 puppeteer 中使用 cheerio 解析 html 文档 和 在浏览器使用 jquery 的表现不同
- node 中异步流程控制与错误处理
开始爬取需要的数据
爬取中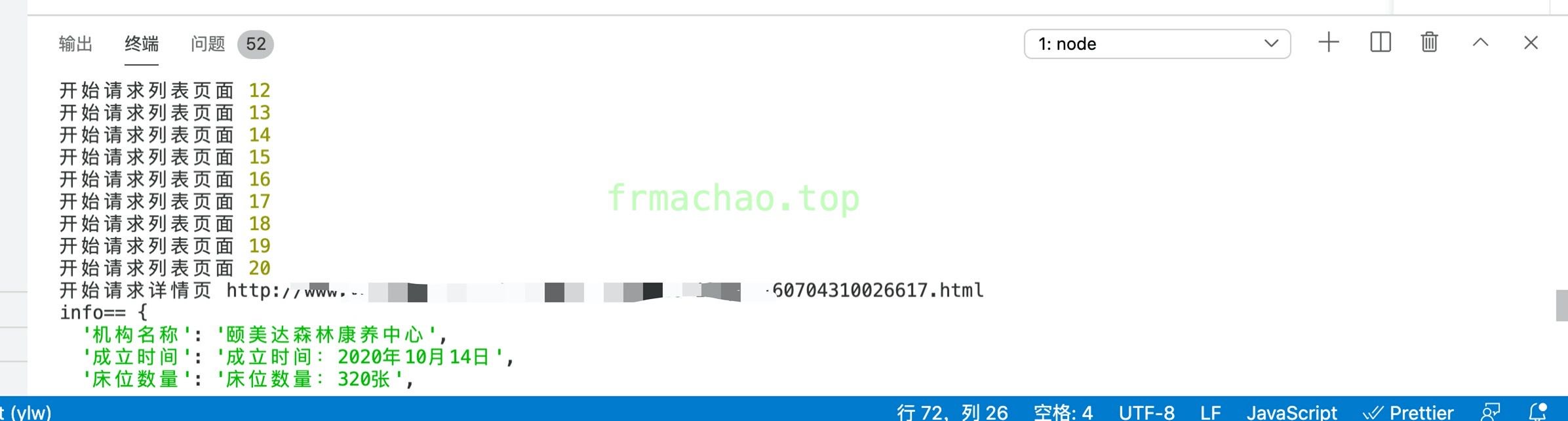
导出为 excel
其实就是一个功能及其简单的玩具爬虫
完整的代码 去掉注释不到 100 行
- 循环列表页面得到跳转到详情页的地址 整理成一个数组
- 循环得到的数组,依次访问对应的页面,将需要的详情页上的数据整理成数组
- 导出数组为 excel
1 | |
参考

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!